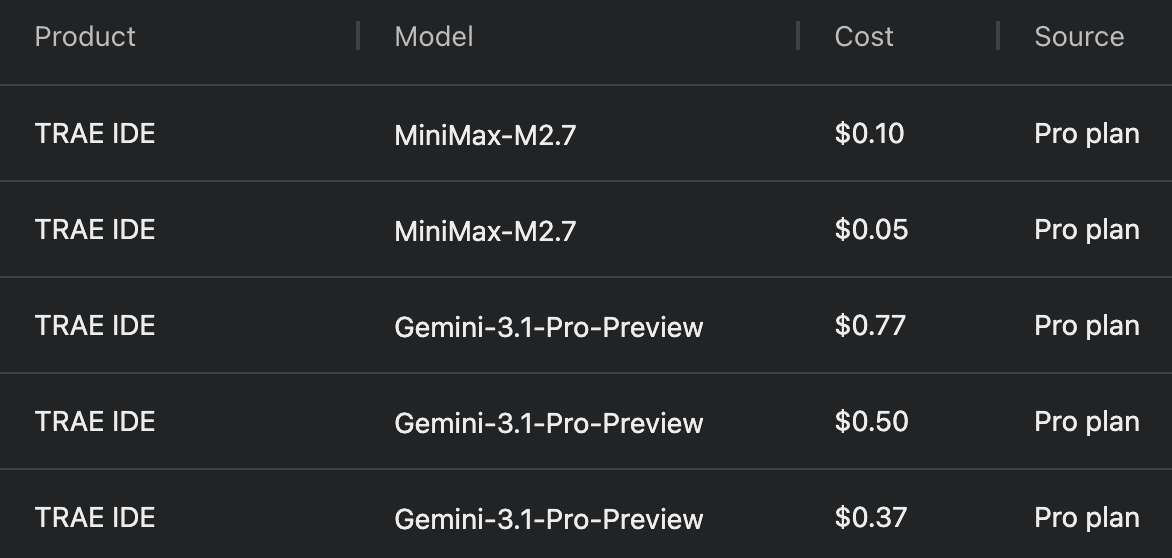
同样的编程任务,Gemini 或 GPT 一次消耗 0.5 美元,国产模型只要 5 分钱。但为啥大家宁可花十几倍的价钱,面对层层封锁也要硬冲?答案是:差距真实存在,但差距的本质不在于参数,而在以下:
真正的差距:是模型"被谁教过"
大模型训练分两步:先预训练(从海量文本里学语言规律),再后训练(从人类反馈里学"什么是好回答")。国产模型的预训练早已追平,但后训练才是决定"品味"的关键。
国外顶级模型在RLHF(人类反馈强化学习)上投入巨大:雇大量领域专家标注数据,让模型反复学习"专家到底怎么思考"。国产模型这一步往往用自动化或低成本标注替代,导致模型学会了"正确的废话",却没学会"高水平的推理模式"。这就是为什么它的回答永远"像学生作业,不像专家判断"。
数据生态:不是英语更好,是高质量内容更多
另一个被忽视的事实是:GitHub、Stack Overflow、ArXiv 上的优质技术内容以英文为主。模型吃的是"语料分布",不是"语言本身"。同样的中文模型,如果训练数据里充斥低质营销号和过期百科,它的"知识品味"天然就低一档。这不是迷信海外,而是内容生态的客观现实。
"堆上下文"为什么没用
有观点说给模型多喂点资料就能弥补。这是误解。模型的智能不是资料的简单累加——就像给它一本博士论文,它的推理水平不会从"高中生"跳到"博士生"。智能密度由训练阶段决定,上下文只能唤醒已有能力,不能凭空创造能力。
写在最后
所以国内模型选择主打性价比是合理的——用 1/10 的成本覆盖 80% 的场景。但在需要真正深度推理的时刻,差距依然真实存在。
你日常用 AI 编程或写作时,感觉国产模型和国外差在哪?来聊聊你的真实感受。